Method
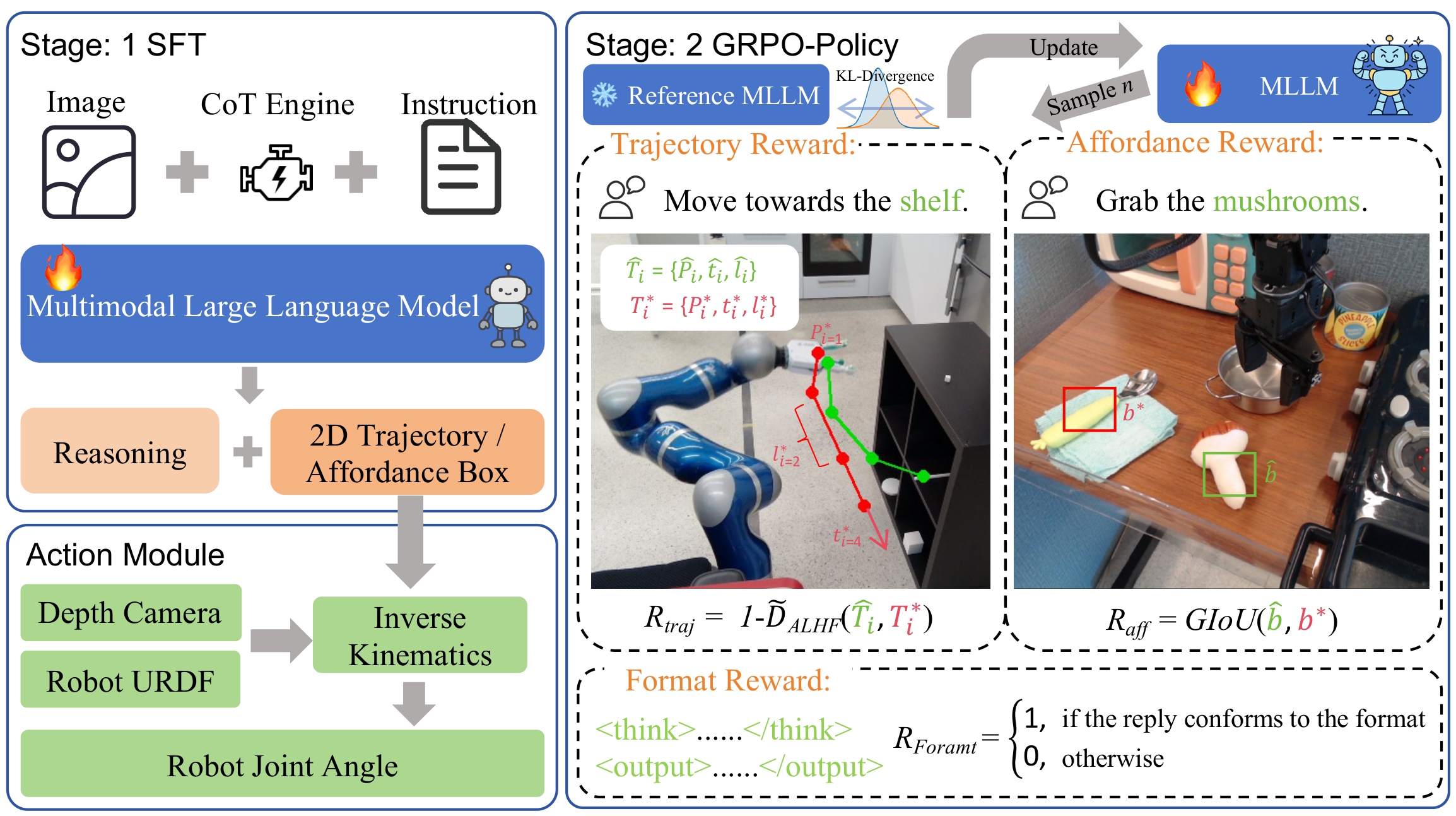
Overall architecture of VLA-R1. The system operates in two stages. Stage I applies supervised fine-tuning (SFT) augmented with Chain-of-Thought (CoT) supervision to endow the multimodal model with foundational reasoning, enabling it to generate trajectories or affordance regions conditioned on images and instructions; a downstream control stack then converts these outputs into joint-level robot commands. Stage II introduces reinforcement learning with verifiable rewards (GRPO) to further refine both reasoning quality and action execution, yielding more robust cross-task generalization and resilience in complex scenarios.